Results
Overview of the Experiment
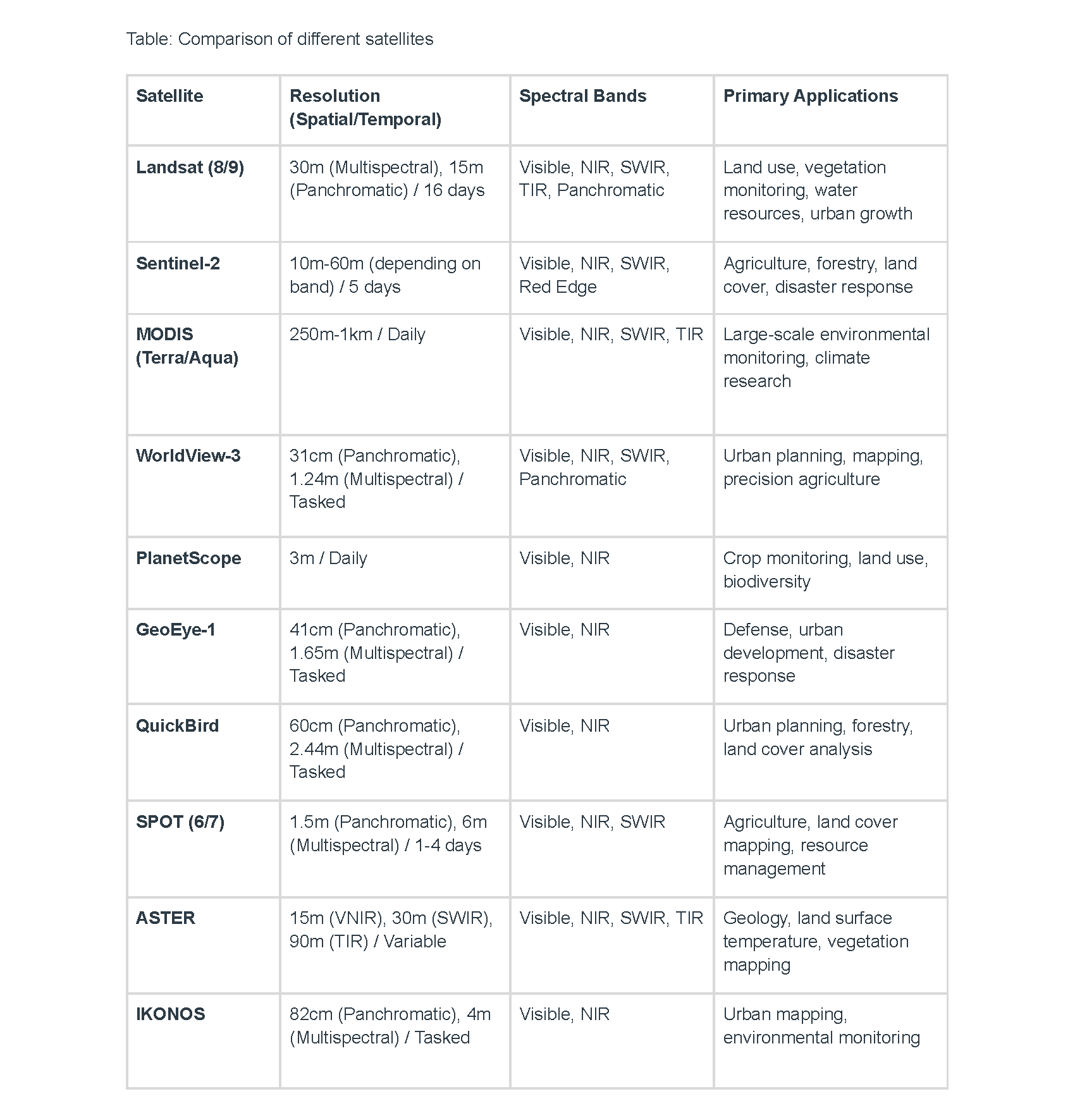
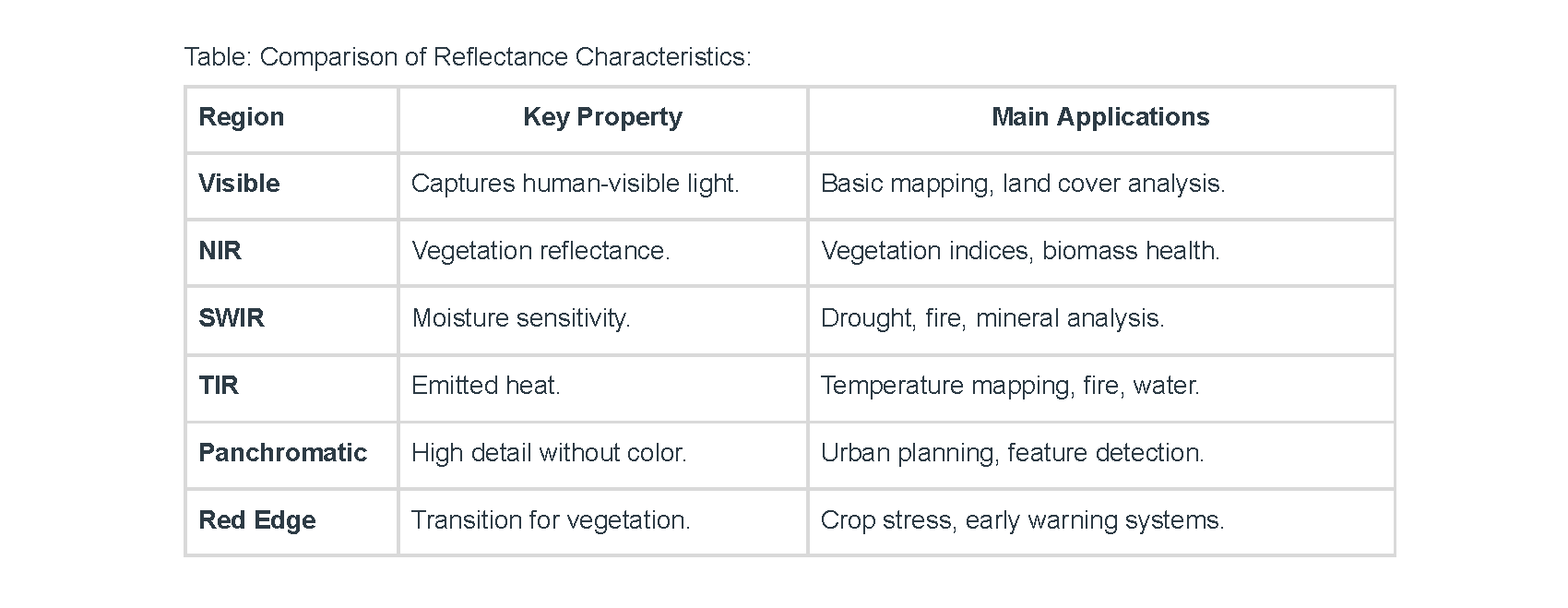
This experiment evaluates the performance of fine-tuned models using different masking strategies on Sentinel-2 satellite imagery.
The models were trained using either all Bands, elaborated on analysis Part A, or only RGB channels, elaborated on analysis Part B,
from Sentinel-2 images, each with two masking approaches:
High Reflectance Mask: Setting all values in the masked pixels to a random number between 0.7 and 1 (same value across all bands);
Null Mask: Setting the masked pixel values to -9999.
In total, there are 4 scenarios studied.
Result Analysis Part A - Masking Strategies when all bands from Sentinel-2 are available
Overall Performance
The results show that both masking strategies yield relatively high performance, with mean F1-scores and accuracies above 0.7 for both approaches. However, the High Reflectance Mask consistently outperforms the Null Mask:
High Reflectance Mask: Mean F1-Score = 0.78, Mean Accuracy = 0.79
Null Mask: Mean F1-Score = 0.71, Mean Accuracy = 0.73
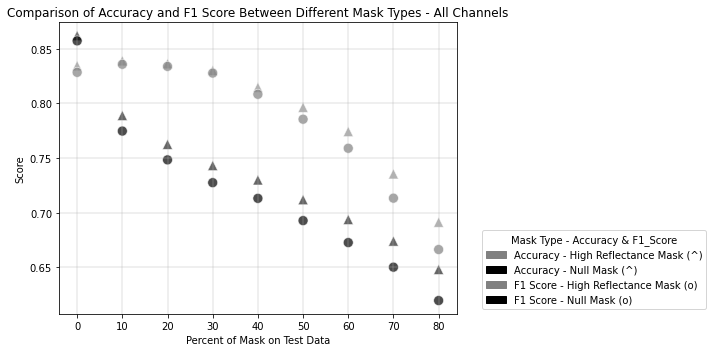
Here are the accuracy and F1-Score results for each trained model evaluated by the range of percentages of masked pixels:
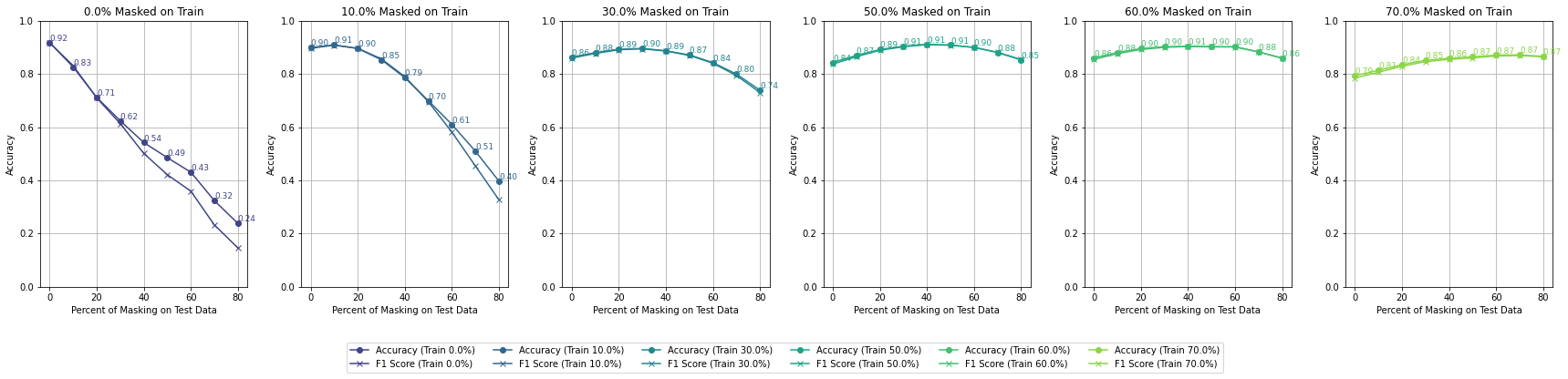 Accuracy by Different Percent of Masking on Training - All Bands - High Reflectance Mask
Accuracy by Different Percent of Masking on Training - All Bands - High Reflectance Mask
 Accuracy by Different Percent of Masking on Training - All Bands - Null Mask
Accuracy by Different Percent of Masking on Training - All Bands - Null Mask
Null masking likely introduces discontinuities in data, reducing the ability to interpolate masked regions effectively. This could lead to lower overall accuracy compared to the high reflectance mask. By setting masked pixels to reflectance values (0.6 to 1), the strategy mimics spectral properties seen in highly reflective surfaces (e.g., water, urban materials). This helps maintain continuity in spectral data, enabling models to learn patterns in the context of realistic reflectance values. This explains the consistently higher accuracy.
In addition, Reflectance Mask may act as a form of augmentation, simulating reflective surfaces like snow or water. Null Mask lacks this advantage.
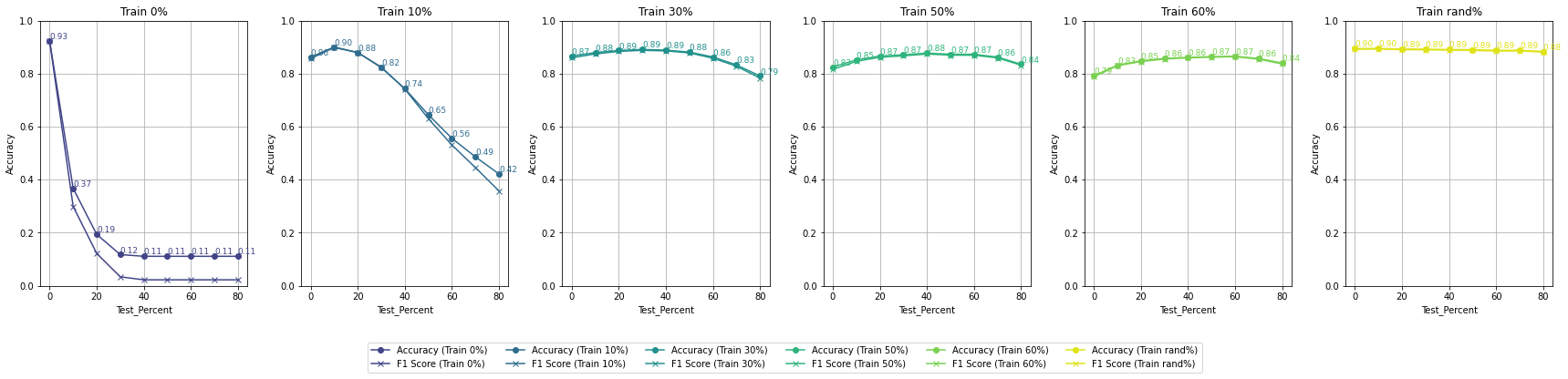
Each plotted line is a model trained on a different percentage of masked pixels
 Accuracy by Different Percent of Masking on Training - All Bands - High Reflectance Mask
Accuracy by Different Percent of Masking on Training - All Bands - High Reflectance Mask
 Accuracy by Different Percent of Masking on Training - All Bands - Null Mask
Accuracy by Different Percent of Masking on Training - All Bands - Null Mask
This suggests that preserving some information in the masked areas (by using high reflectance values) is more productive for the model's learning process than completely nullifying the masked pixels.
Performance Across Classes
To understand how masking strategies affect class-specific performance, I analyzed the Accuracy and F1-scores for each class. The results reveal distinct patterns:
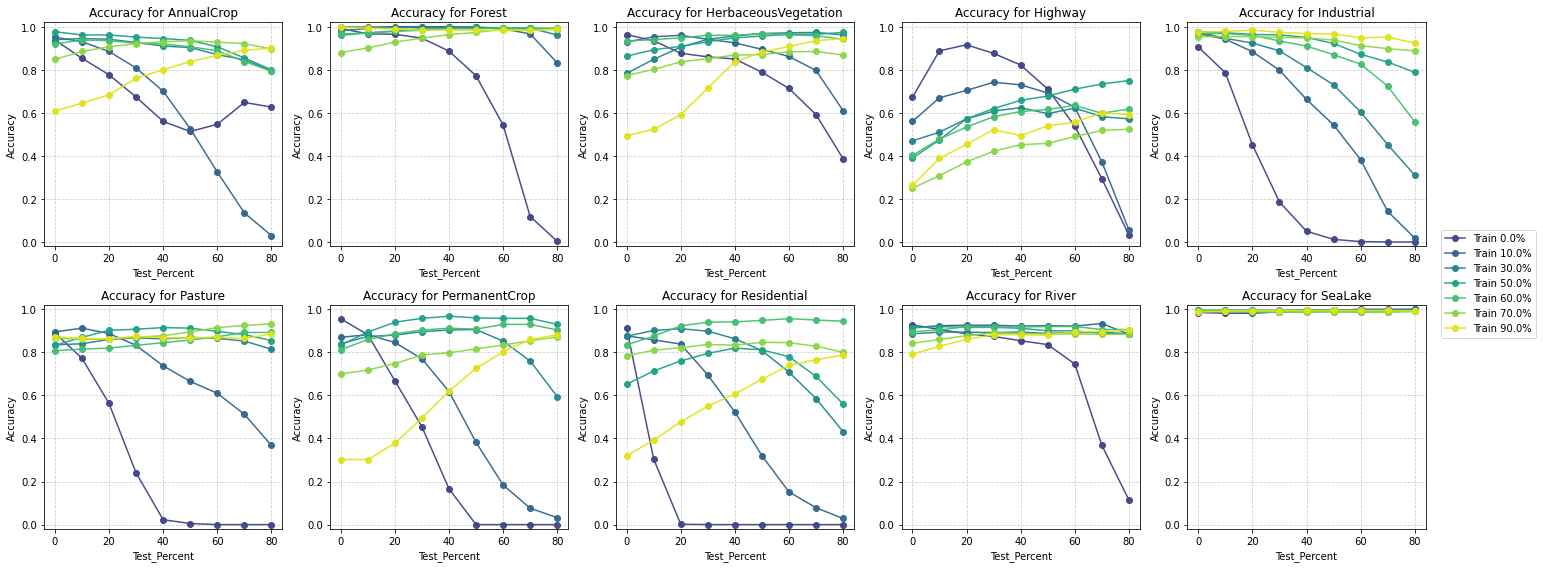 Accuracy by class - All Bands - High Reflectance Mask
Accuracy by class - All Bands - High Reflectance Mask
 Accuracy by class - All Bands - Null Mask
Accuracy by class - All Bands - Null Mask
High Reflectance Classes (e.g., SeaLake, River): Both strategies perform well on these classes, with the high reflectance Mask slightly outperforming. High reflectance values align naturally with these classes, making the high reflectance Mask’s artificial reflectance a better approximation than the Null Mask.
Low Reflectance Classes (e.g., Forest, Pasture): The Null Mask leads to greater inaccuracies in low-reflectance classes. Extreme outliers (-9999) disrupt learned feature distributions, making models less effective in predicting low-reflectance areas.
Transitional Classes (e.g., Herbaceous Vegetation, Residential): These classes are sensitive to both masking strategies, with the high reflectance Mask showing better robustness. The high reflectance Mask maintains spectral patterns for these mixed-use or heterogeneous classes, whereas the Null Mask’s outliers create ambiguities.
Highway Class: Both accuracy and F1 scores are consistently lower compared to other classes. Extreme outlier values (-9999) make it difficult for the model to accurately predict highways, which are narrow, linear features often surrounded by heterogeneous land types. The improvement is likely due to the continuity provided by reflectance-like values (0.6–1), which are closer to the spectral characteristics of concrete or asphalt.
This suggests that preserving some information in the masked areas (by using high reflectance values) is more productive for the model's learning process than completely nullifying the masked pixels.
Result Analysis Part B - Masking Strategies when only RGB bands are available
Overall Performance
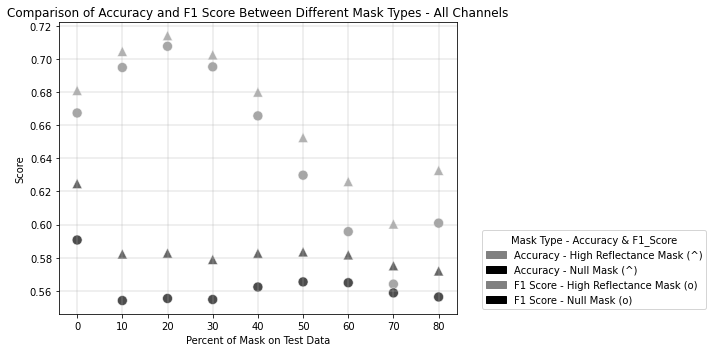
The results show that high reflectance masking consistently outperforms null masking across all masking percentages.
At 0% training mask (baseline), both strategies achieve similar accuracy (84.7%), but the performance gap widens as masking increases.
Models trained with high reflectance masking retain higher robustness and accuracy compared to those trained with null masking, especially as test masking percentages grow.
Here are the accuracy and F1-Score results for each trained model evaluated by the range of percentages of masked pixels:
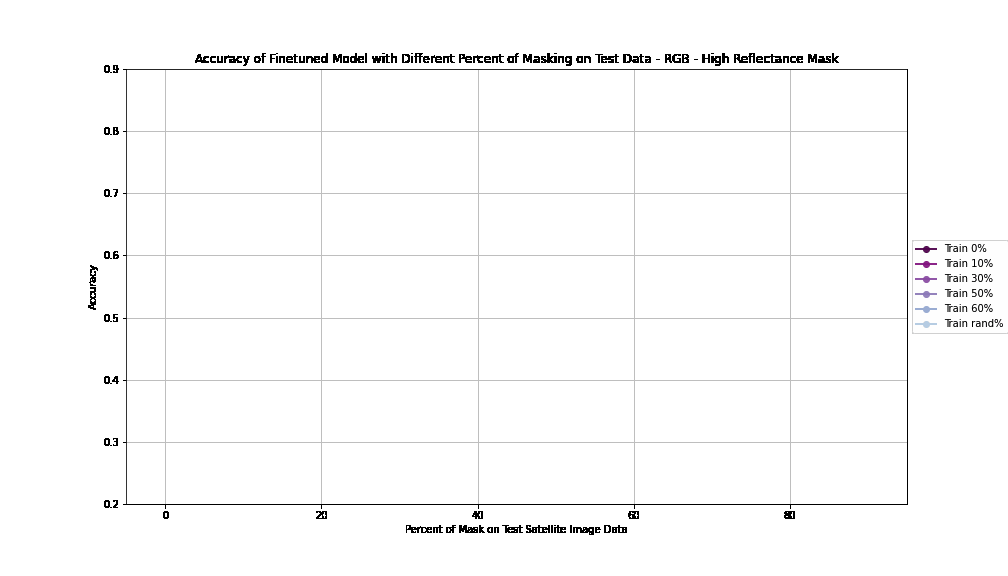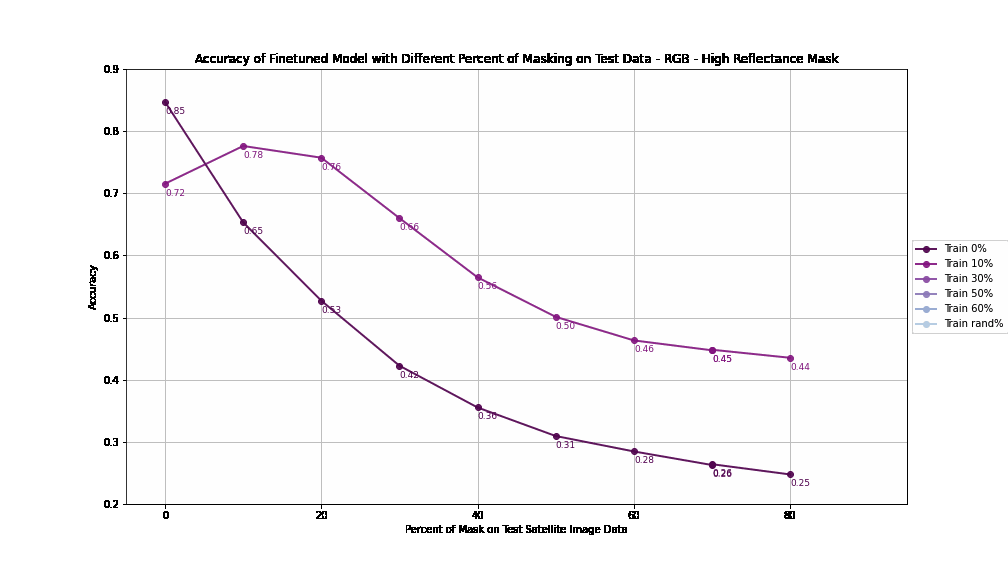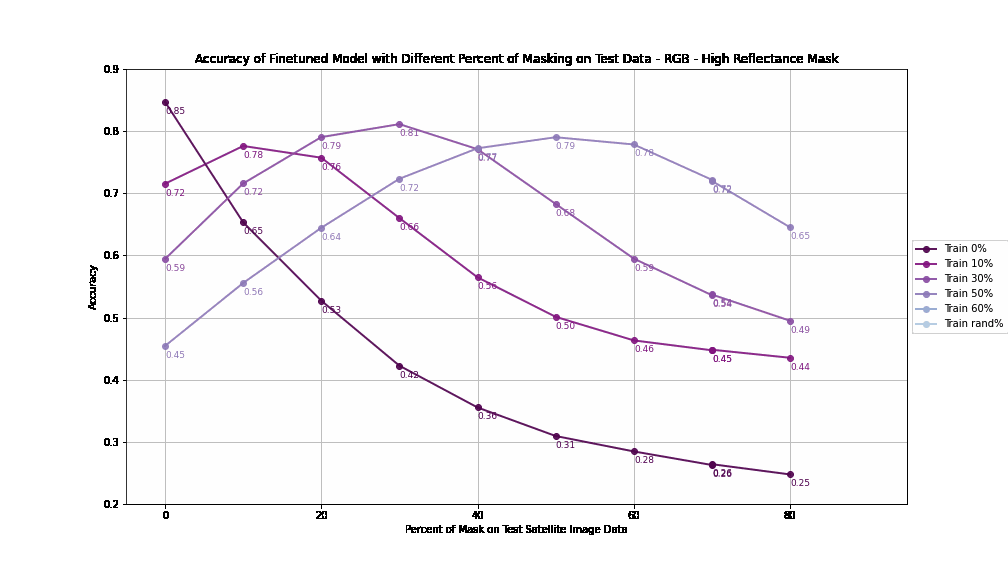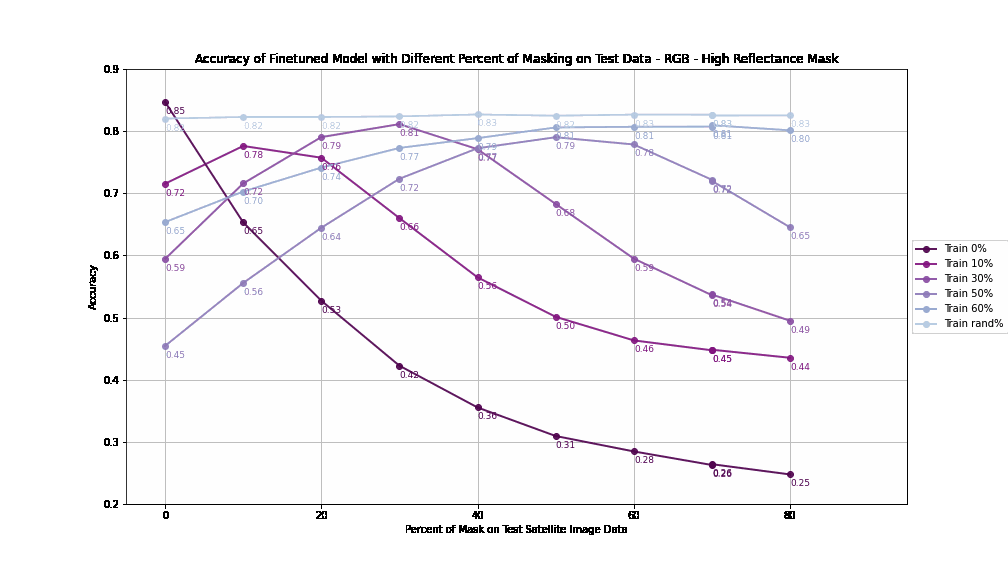
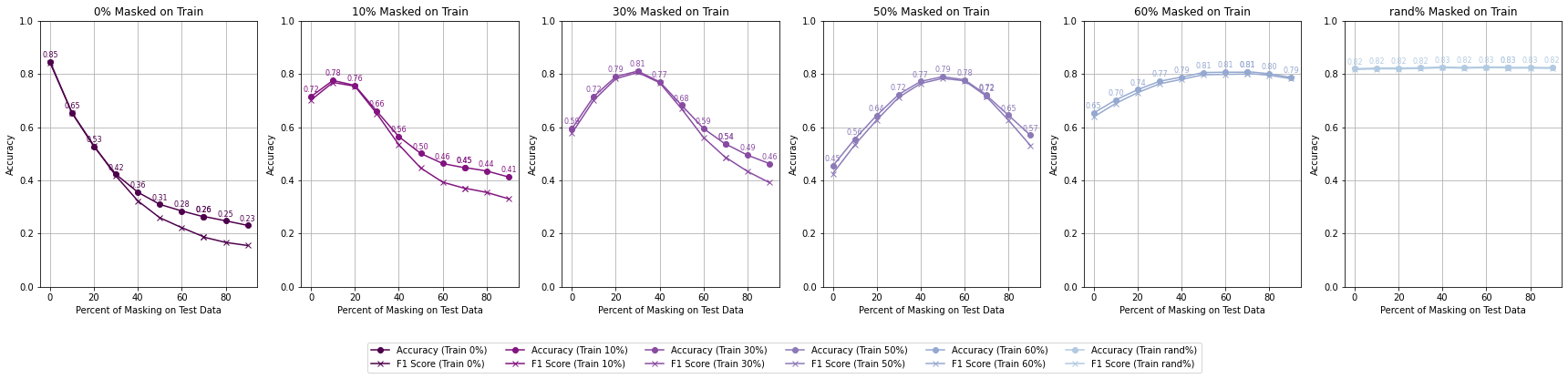 Accuracy by Different Percent of Masking on Training - RGB - High Reflectance Mask
Accuracy by Different Percent of Masking on Training - RGB - High Reflectance Mask
 Accuracy by Different Percent of Masking on Training - RGB - Null Mask
Accuracy by Different Percent of Masking on Training - RGB - Null Mask
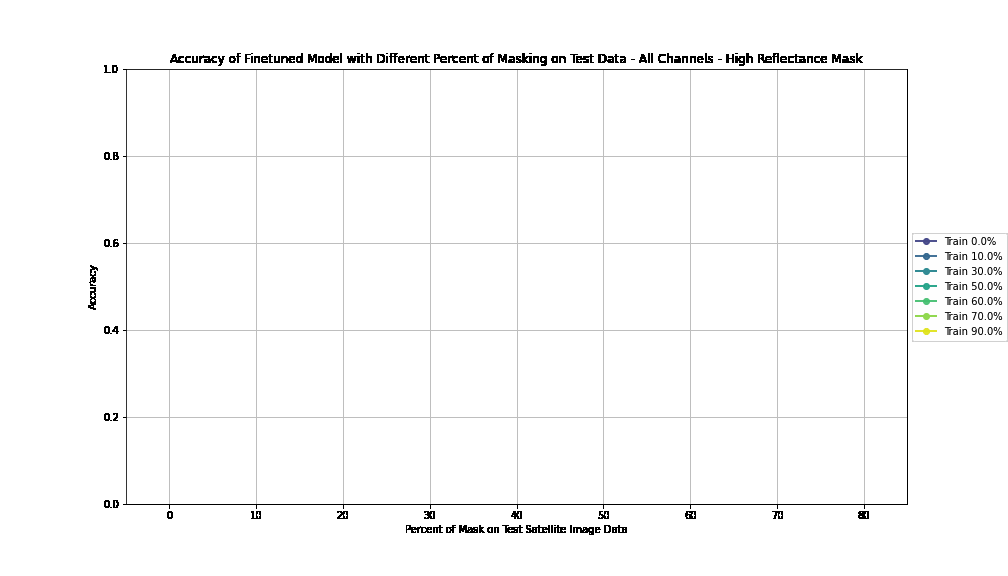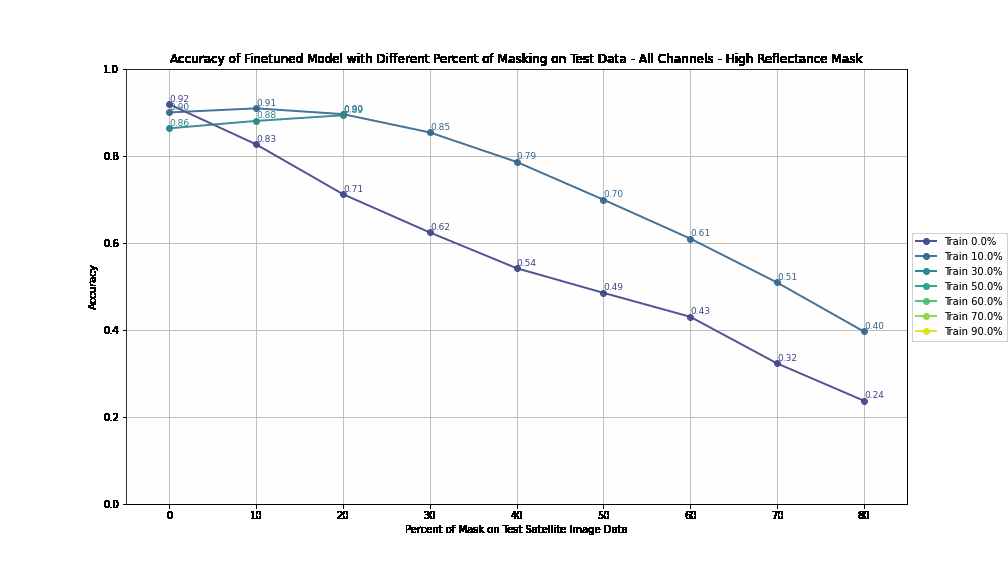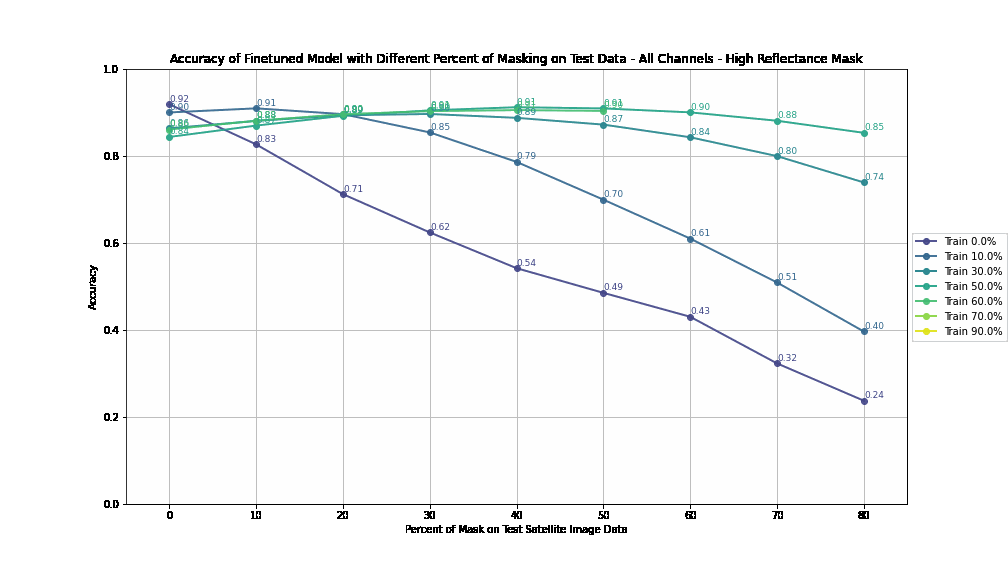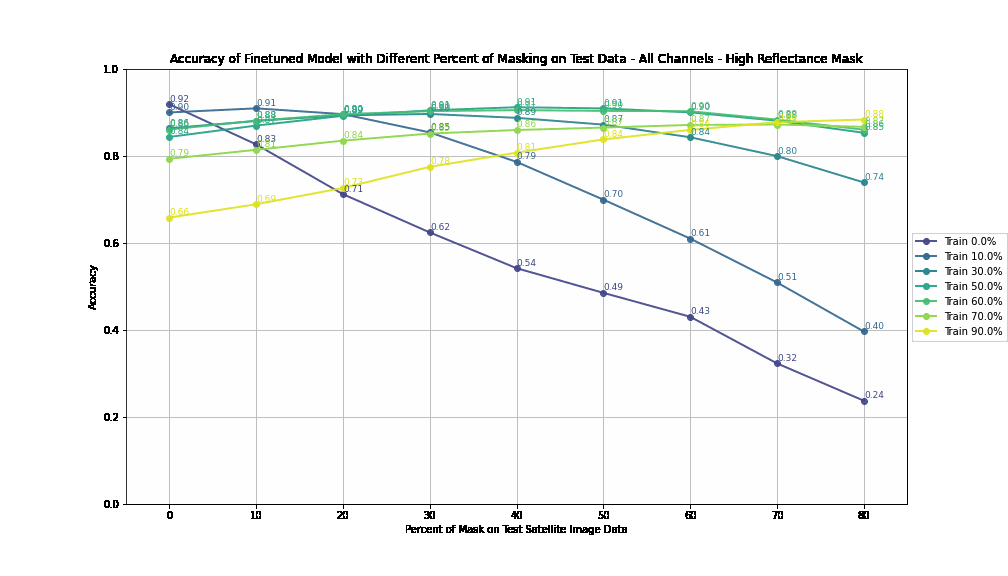
For High Reflectance Masking, performance degradation is gradual and controlled with increasing test masking percentages. Models maintain reasonable accuracy (>70%) even with 30% masked pixels in the test data if trained with at least 10% masking. When models are trained with up to 60% masked data, they still achieve >60% accuracy when tested under similar masking conditions, showcasing resilience.
For Null Masking, performance drops steeply with increasing test masking percentages, reflecting a lack of adaptability. Accuracy falls below 50% when test masking exceeds 40%, indicating poor handling of masked data. This rapid deterioration suggests that the extreme negative values (-9999) used in null masking disrupt the model’s generalization ability.
Each plotted line is a model trained on a different percentage of masked pixels
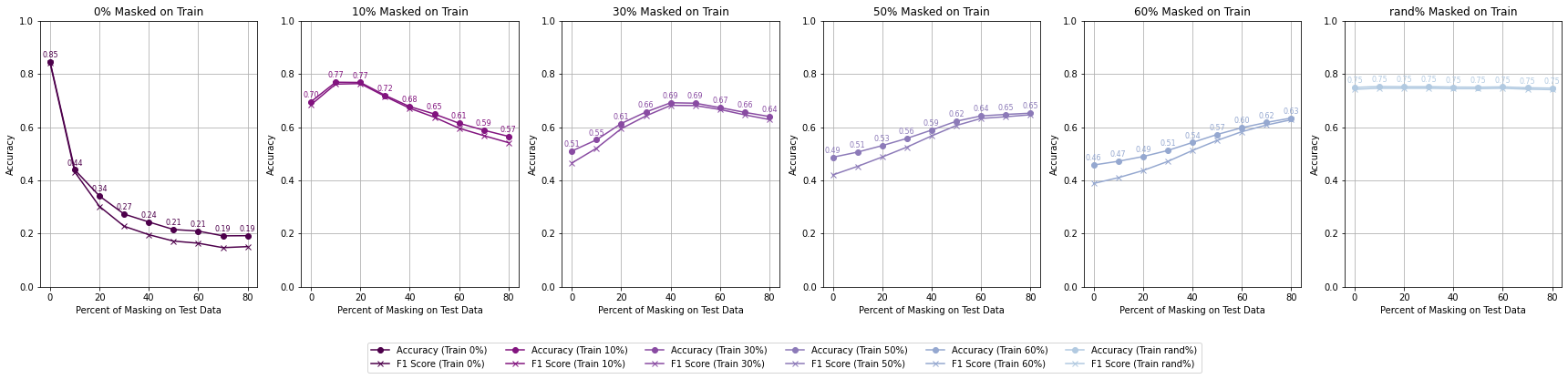
 Accuracy by Different Percent of Masking on Training - RGB - High Reflectance Mask
Accuracy by Different Percent of Masking on Training - RGB - High Reflectance Mask
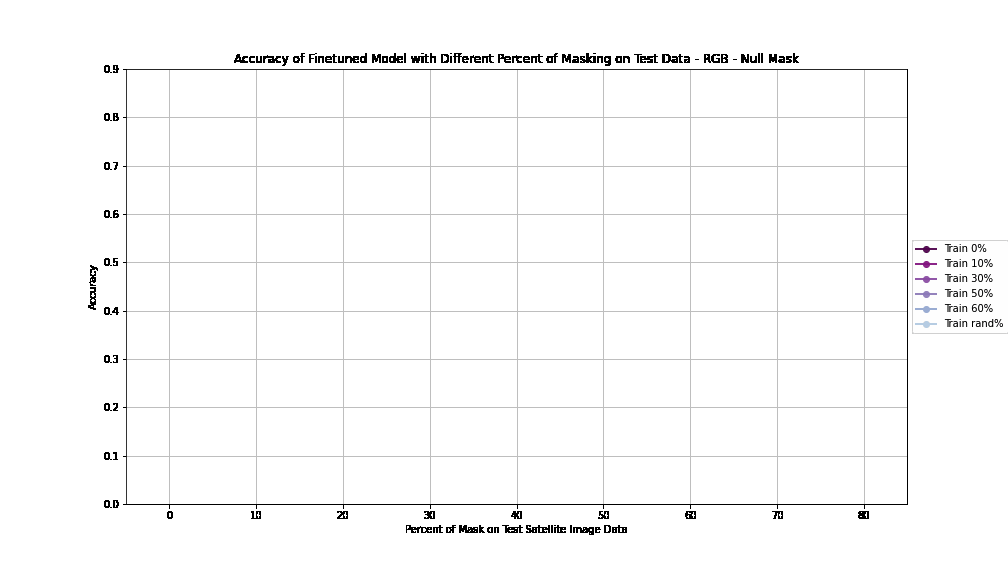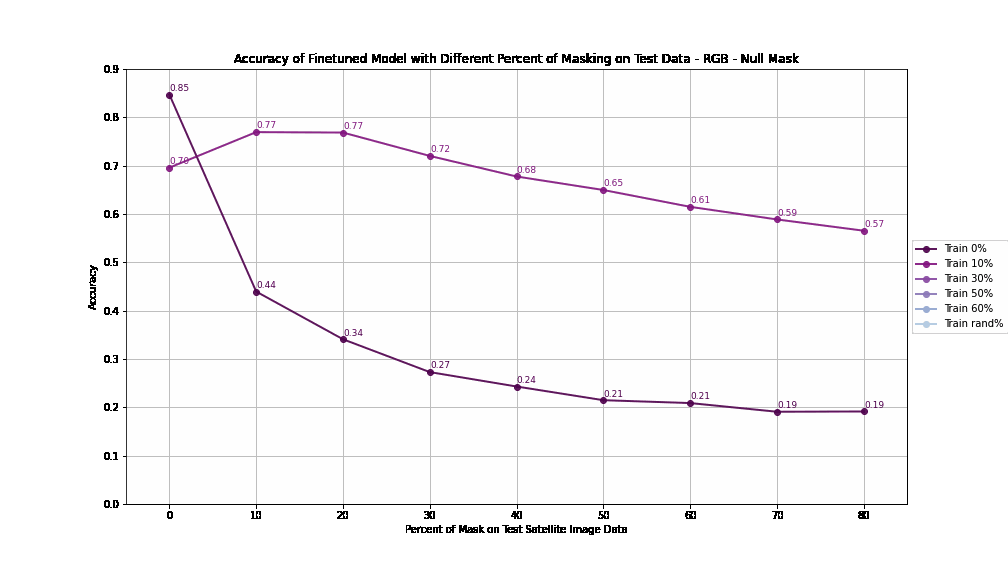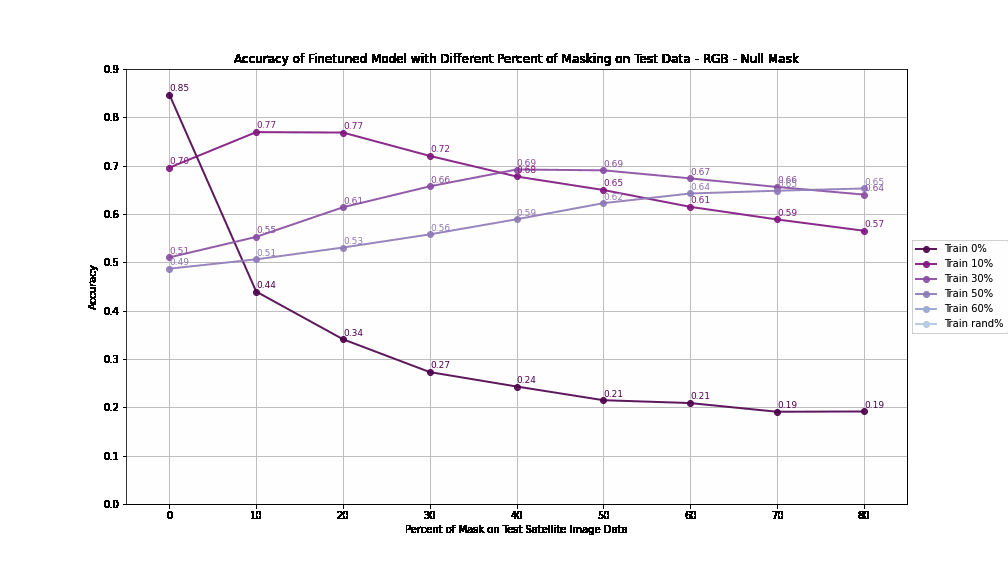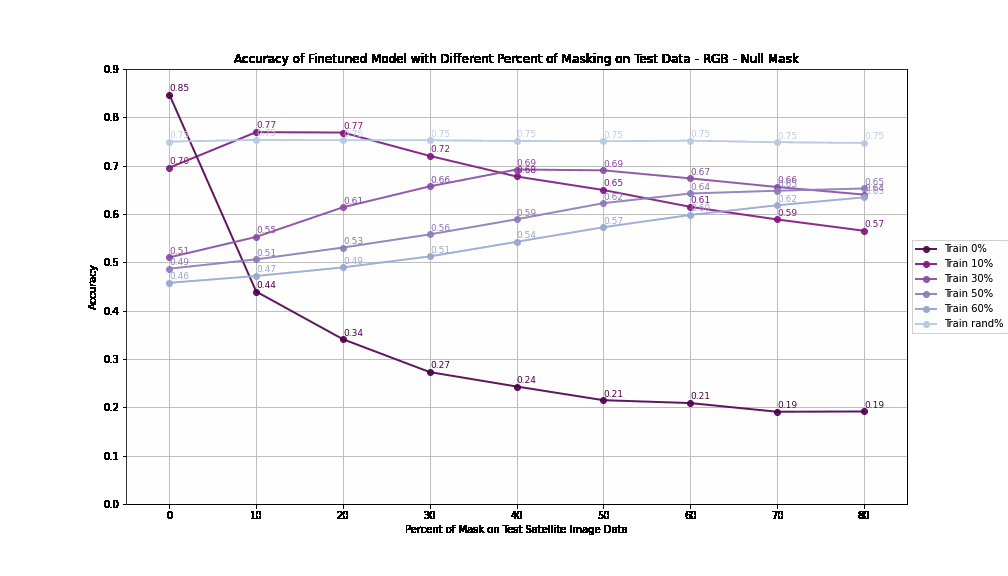 Accuracy by Different Percent of Masking on Training - RGB - Null Mask
Accuracy by Different Percent of Masking on Training - RGB - Null Mask
High reflectance masking enables better generalization to higher masking percentages, showing adaptability across varying test conditions. Training with 30-50% masked pixels offers the optimal balance between performance and robustness, allowing models to adapt to both low and high levels of test masking. Null masking, on the other hand, fails to generalize effectively to test conditions beyond the training mask percentage.
The best performance is achieved when models are trained with a random percentage of masking. This exposure to occlusions handle missing data more effectively, leading to improved generalization.
Performance Across Classes
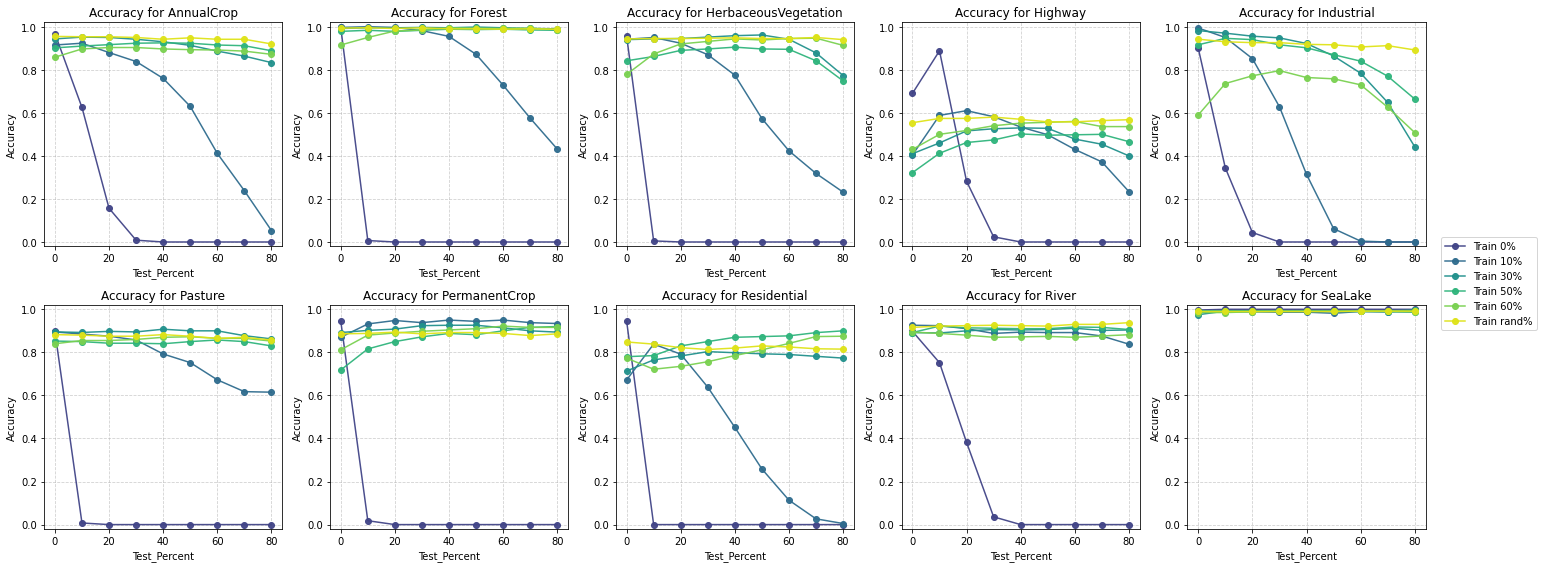
Same as for part A, to understand how masking strategies affect class-specific performance when only RGB bands are available, I analyzed the Accuracy and F1-scores for each class. The results reveal distinct patterns:
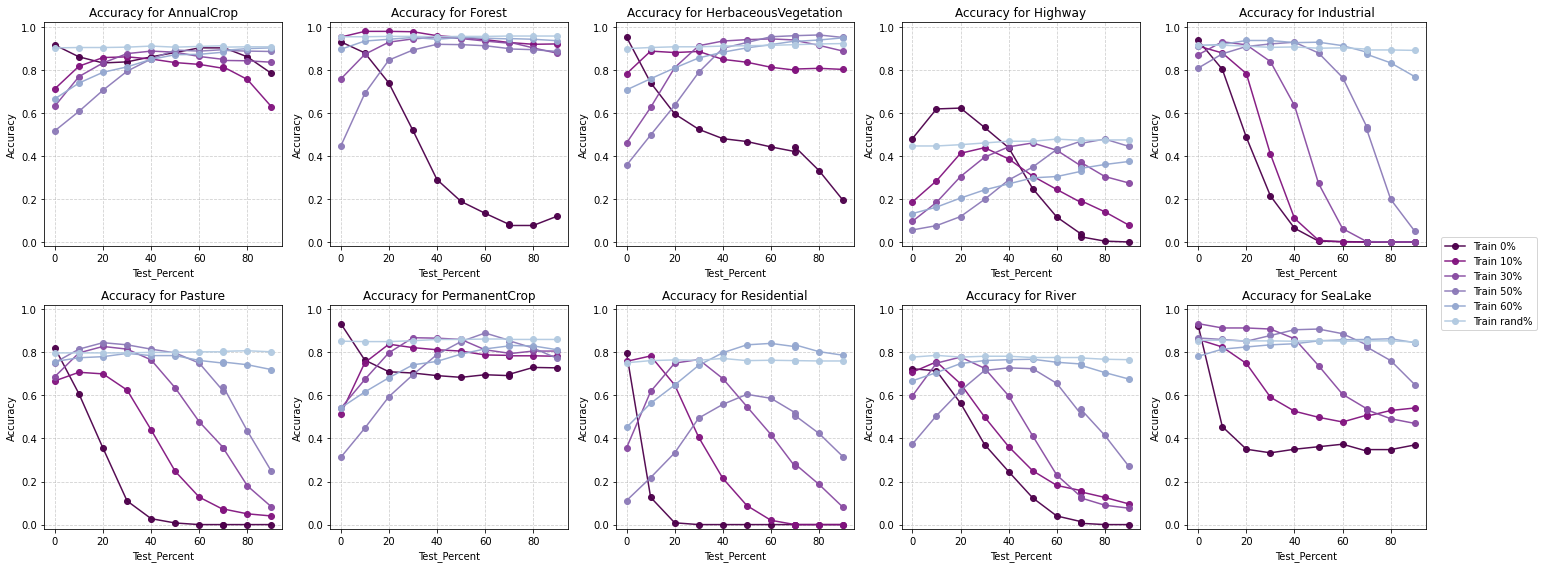 Accuracy by class - RGB Bands - High Reflectance Mask
Accuracy by class - RGB Bands - High Reflectance Mask
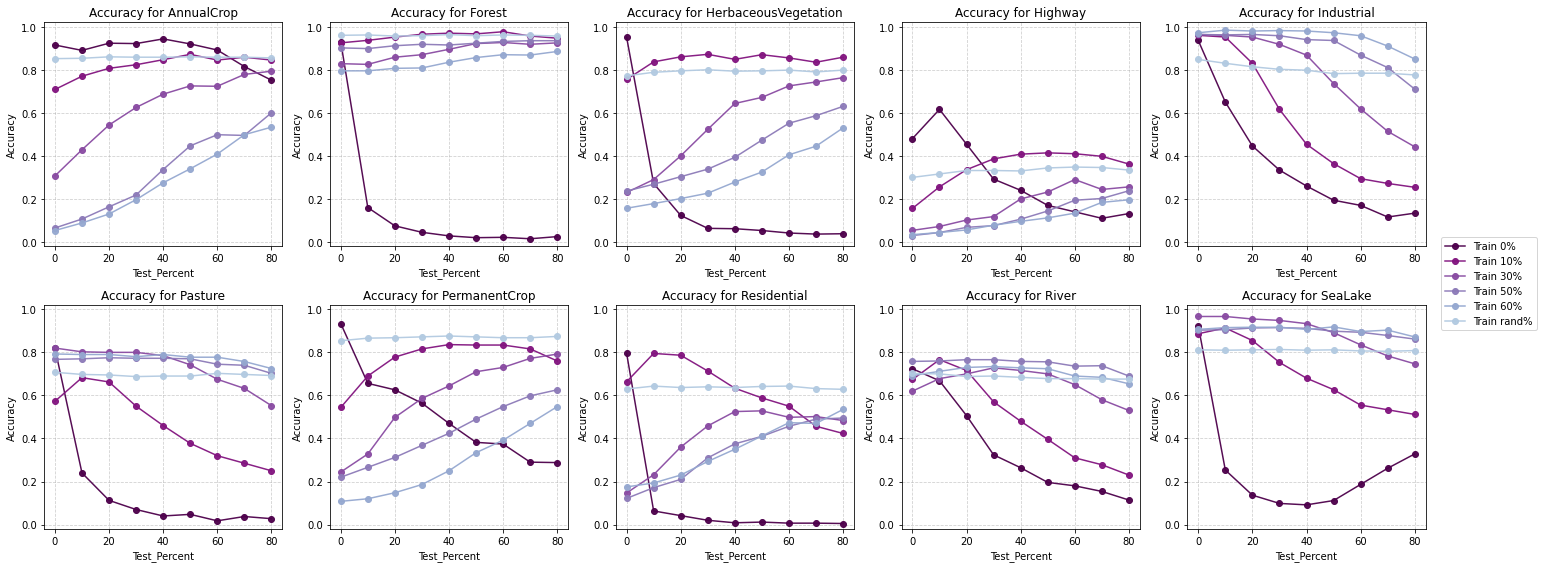 Accuracy by class - RGB Bands - Null Mask
Accuracy by class - RGB Bands - Null Mask
High reflectance masking demonstrates superior class-wise performance, achieving better F1 scores across most land cover categories.
It is particularly effective for complex and nuanced classes like Residential and Industrial areas, which are challenging to classify.
In challenging categories such as Rivers and Highways, high reflectance masking maintains more stable accuracy and F1 scores, indicating its robustness in diverse scenarios.
The results strongly favor high reflectance masking as the superior strategy for handling masked pixels in satellite imagery classification tasks. Its ability to:
gradually degrade performance with increasing masking;
generalize well to unseen test conditions, and
maintain robust class-wise performance makes it a highly effective and practical choice compared to null masking.
The findings emphasize the importance of realistic masking strategies, such as high reflectance masking, for improving the robustness and accuracy of machine learning models in remote sensing applications.
 Side-by-side panels to show land use/land cover (LULC) change from 2014-2018. Screenshot from Dynamic LULC Change, Chesapeake Conservancy taken 25-October-2022.
Side-by-side panels to show land use/land cover (LULC) change from 2014-2018. Screenshot from Dynamic LULC Change, Chesapeake Conservancy taken 25-October-2022.